
Qu’est-ce que l’indexation en SEO ?
En référencement naturel, l’indexation peut être résumée simplement par le fait de recenser et faire apparaître une ressource web (Page, Pdf, image…) au sein des pages de résultats d’un moteur de recherche.

L’indexation joue un rôle essentiel dans la visibilité d’un site internet et son acquisition de trafic SEO. Une page web (URL) n’étant pas répertoriée au sein de l’index d’un moteur de recherche n’a que peu de chance d’être consultée par les utilisateurs, sauf en « Direct », un canal nécessitant déjà une forte notoriété web du site.
Toutefois, il est souvent nécessaire de maîtriser ou prévenir l’indexation de certaines pages d’un site web afin de ne servir que les contenus ayant un intérêt à l’utilisateur ainsi qu’au moteur de recherche.
En effet, pour des raisons d’Expérience Utilisateur (UX) ou de structuration, un site n’est pas construit uniquement de pages utiles. Il est donc important d’indiquer aux moteurs de recherche les répertoires et pages web n’ayant pas d’intérêt sémantique ou de maillage interne, afin qu’il ne les prenne pas en comptes lors de son crawl et ne les indexe pas.
Outre la maîtrise de l’indexabilité, c’est un facteur prépondérant dans la rationalisation du Budget Crawl des moteurs de recherche (contingent temporel attribué à une site web en fonction divers facteurs), et sa qualité.
Comment maîtriser l’indexation des pages d’un site internet ?
Les bénéfices SEO d’une meilleure qualité d’indexation et de crawl sont importants pour les sites web à forte volumétrie de pages, mais aussi pour les plus petits, il est donc crucial de l’optimiser.
Voici comment il est possible de prendre la main sur l’indexation et le crawl :
Les balises méta robots

La balise « méta robots » est une balise HTML généralement située au sein de la balise <head> d’un document HTML. Elle permet de donner une instruction relative à l’indexation et au suivi des liens internes d’une pages web.
C’est (avec les X-robots tags, plus bas), le moyen de plus efficace et rapide pour un page web de :
- La rendre indexable,
- Prévenir son indexation,
- La désindexer (correctif),
- La bloquer au crawl,
- La rendre crawlable.
Les combinaisons d’instructions possibles des balises méta robots :
Le but est de donner une instruction de crawl et d’indexation spécifique au robot du moteur de recherche pour maîtriser son comportement :
- « noindex, follow » : Le robots n’indexe pas la page web mais va suivre les liens internes qui y sont présents –> à utiliser pour des pages annexes venant renforcer une page mère sans l’indexer, mais en tenant compte de son rôle dans le SEO d’un site.
- « noindex, nofollow » : Le robots n’indexe pas la pages et ne suit pas ses liens internes –> pages sans intérêt SEO
- « index, follow » : le robots indexe la page web et suit son contenu et ses liens internes –> pages utiles au référencement naturel : Sémantique, maillage interne, forte popularité externe…
- « index, nofollow » : Le robots indexe la page mais ne suit pas son contenu et liens internes –> pages statiques étant nécessaires d’indexer, mais n’ayant pas d’utilité SEO.
Attention ! Ces instructions ne sont visibles qu’à partir du moment ou le crawler (spider) peut identifier la balise méta au sein du code HTML de la page. Les balises ne sont donc pas visibles, si les pages sont bloquées au robots.txt.
Les entêtes HTTP : X-Robots Tag
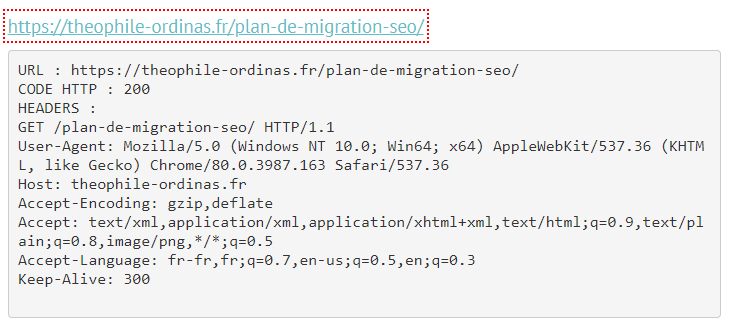
Les entêtes HTTP X-Robots Tags sont rendues visibles aux moteurs via le serveur.
Elles jouent le même rôle que les balises méta robots, mais sont moins pratiques à mettre en place, car leur déploiement se passe coté serveur et non au sein de l’HTML.
Pour le SEO, les instructions utiles sont donc les mêmes :
- « index, follow »
- « index, nofollow »
- « noindex, follow »
- « noindex, nofollow »
Plus d’infos sur le déploiement des balises méta robots et entêtes X-Robots Tag rendez-vous sur :
https://developers.google.com/search/reference/robots_meta_tag?hl=fr
Les balises canonicals
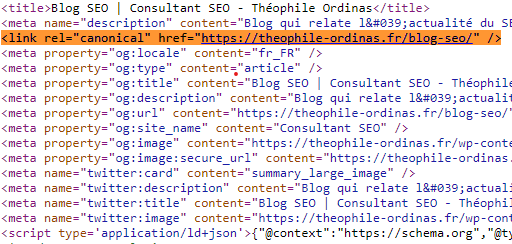
Généralement utilisées pour maîtriser une duplication de pages due à un versioning difficilement de contrôlable, la balise Canonical permet de spécifier la version de la page qui doit être indexée.
Elle peut donc servir le cas échéant, d’outils de désindexation mais cela n’est pas conseillé car beaucoup moins réactif.
Voici un exemple concret du déploiement cité, pour une société souhaitant passer tout un site web d’une extension de domaine à une autre.
https://doyouno.com/ —– Canonisé sur —— « https://doyouno.fr/ »
Cela permet d’indiquer aux moteurs de recherche que cette page web doit être indexée sous le .fr. Il va donc amorcer une désindexation (lente) de toutes les pages du site en « .com » pour passer au « .fr » au fur et à mesure du crawl de chacune des pages du site.
Dans ce cas concret, la meilleure façon de procéder aurait été de déployer un plan de migration et des redirection 301. Entre temps le déploiement a changé et s’est complexifié avec du JavaScript et du cloacking.
Le robots.txt
« Mieux vaut prévenir que de guérir«
Le robots.txt est un petit fichier txt posé à la racine d’un site web. Il doit toujours être accessible via cette adresse : https://monsiteweb.fr/robots.txt
Ce fichier est censé donner des instructions relatives au comportement de crawl des moteurs de recherche.
Diverses instructions peuvent y être renseignées afin d’optimiser le crawl et prévenir l’accès (donc l’indexation) de certaines ressources, répertoires sensibles ou pages web en amont de leur indexation.
Le robots.txt doit renseigner la ou les adresse(s) de votre ou vos sitemap.xml.
Exemple de robots.txt :
User-agent: * Disallow: /rep-one/ User-agent: Googlebot Disallow: /rep-two/ Allow: /rep-two/page-1/ Disallow: /rep-6/azerty* Disallow: /search/ Disallow: /?=query* Sitemap: https://monsiteweb.fr/sitemap.xml
Petite traduction :
- User-agent: * –> voulant dire que les instructions qui suivent s’applique pour tous les spiders des moteurs de recherche.
- User-agent: Googlebot — > permet de spécifier un comportement pour un user-agent spécifique, ici celui de Google.
- Disallow: –> le répertoire ou la page cible ne doit pas être crawlé.
- Allow: –> permet d’outrepasser l’instruction « Disallow: » d’un répertoire, pour que le moteur puisse crawler un sous-répertoire ou une sous-page importante.
- Disallow: /rep/azerty* : –> blocage de toutes les ressources débutants par « azerty » dans le rep-6.
- Disallow: /?=query* : –> blocage d’un paramètre spécifique et ses potentielles combinaison.
Comme cité plus haut, le robots.txt prévient l’accès à des ressources, donc il empêche de lire le code HTML des pages.
Par conséquent, si vous souhaiter désindexer des ressources via des « méta robots » ou autres balises HTML, les répertoires et pages ne doivent aucunement être bloquées au robots.txt. Si c’est le cas, vos pages sont certainement vouées à rester indexées indéfiniment.
Même si majoritairement respecté, le robots.txt peut être outrepassé par certains robots d’indexation et il n’est pas rare de retrouver des ressources (même bloquées) au sein des SERPs.
La désindexation et mise à jour d’index par redirection
Deux types de redirections permettent de désindexer ou mettre à jour assez rapidement l’index d’un site au sein d’un moteur :
- La redirection 301 : dans le cas d’une migration, d’une refonte, d’un changement d’arborescence, les 301 permettent de mettre à jour l’index de Google via des redirections permanentes vers vos nouvelles URLs sans user de 404.
- La redirection 410 : le statut code « 410 Gone » permet une désindexation plus rapide et efficace que les 404 en indiquant directement aux robots d’indexation que la ressource n’est et ne sera plus disponible.
Voir : Plan de migration et refonte
Quelles méthodes d’indexation/désindexation privilégier en SEO ?
Indexation :
Une site web est indexable à partir du moment ou il est déclaré et accessible par les spiders des moteurs de recherche. Ils vont crawler votre site et déterminer suivant les règles citées plus haut quelles pages de votre site indexer et parcourir.
Initialement, en SEO, l’indexation d’un site est intimement liée aux crawls d’autres sites web vous mentionnant via des liens externes ou backlinks. Le crawler passe sur une pages faisant référence à un de vos contenus et suit ce lien vers votre contenus puis l’index. C’est en référencement naturel, la première méthode d’indexation (le crawl du web).
Pour un site vierge de popularité, ne faisant donc pas l’objet de backlinks, il est nécessaire de passer par la Google Search Console. L’outil SEO va permettre et de déclarer votre site web et toutes ses ressources via la soumission d’un sitemap.xml. Google saura que le site existe et l’indexera.
La meilleure méthode d’indexation restant naturelle ! Une fois un site mis en production, débuter une mini campagne de netlinking afin d’amorcer la découverte de votre page d’accueil par exemple.
Désindexation :
- Désindexation pour suppression de masse sans équivalence, déchets : Redirection 410,
- Désindexer des pages ciblées : Méta robots ou X-Robots Tag,
- Désindexation de la duplication non maîtrisée : balise Canonical,
- Désindexation temporaire : outil de suppression de pages de la Google Search Console.